
北京市高级别自动驾驶示范区工作办公室介绍,正式开放国内首个无人化出行服务商业化试点。至此,国内无人化出行服务从示范运营迈入商业化试点新阶段。

omg,所以自动驾驶真的要来了吗?
男司机女司机老司机新司机们,都可以在车上开心地吃火锅、唱曲儿、搓麻将,再也不用眼观六路耳听八方时刻保持神经紧绷了吗?

但是,这都是自动驾驶的最高状态,以我们目前技术水平还无法实现。
关于自动驾驶,不少人还停留在汽车不用人开自己上路跑的美好想象中,其实这里道道儿多了去了,到底什么是自动驾驶?自动驾驶落地需要哪些技术?我们现在处于自动驾驶的什么阶段?给我3分钟,小编带你火速了解!
认识自动驾驶
01
什么是自动驾驶?
自动驾驶系统是通过车载传感系统感知道路环境,并根据感知所获得的道路、车辆位置和障碍物信息,控制车辆的转向和速度,从而使车辆能够安全、可靠地在道路上行驶并到达预定地点的功能。
这也太教科书了吧?
简单来说,本来以前开车是人类的工作,现在这件事部分或全部交给机器执行了(开车)。
02
自动驾驶整体框架
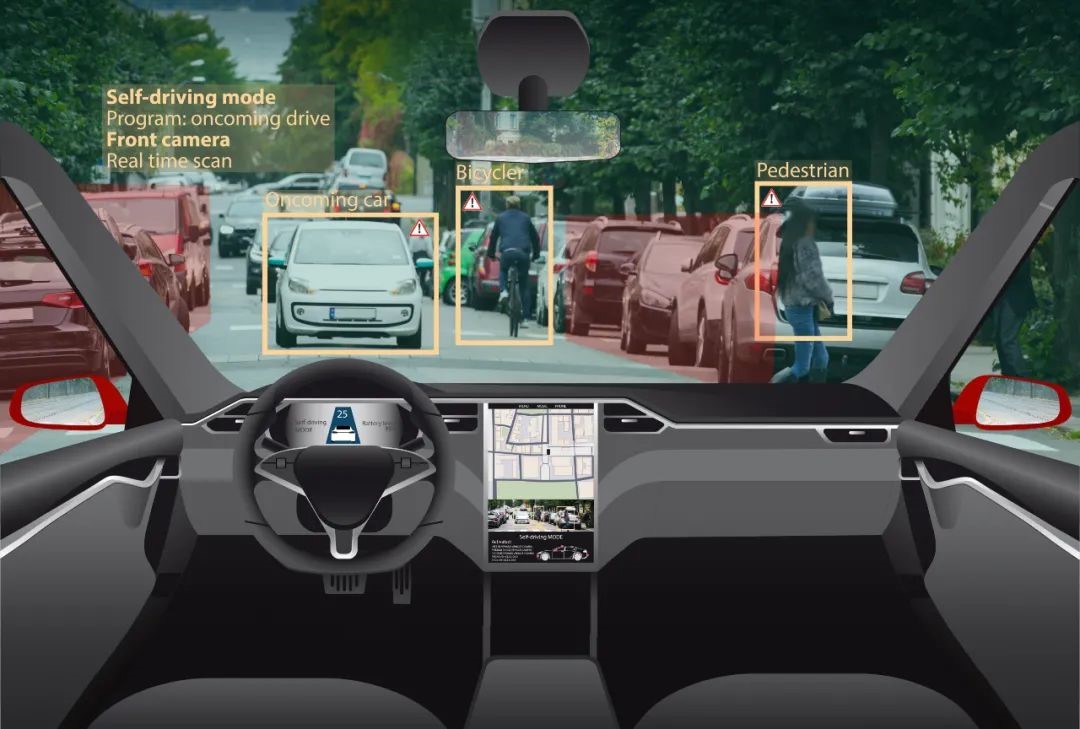
无人驾驶必须包含感知层、决策层和执行层三个方面,它们分别代替了人类的眼睛、大脑和手脚。
▶感知层,通过传感器(激光雷达、摄像头、毫米波雷达、高精地图等)采集驾驶员行驶过程中涉及的驾驶信息;
▶决策层,基于获取的信息进行计算,制定相应控制策略;
▶执行层,执行接收的控制策略,包括加减速、转向等。
03
自动驾驶六大级别
国际上将自动驾驶从l0到l5分为6个级别,等级越高,自动化程度越高。以下是这些级别的具体划分:
l0是车道偏离预警,基本只能提个醒,防止你开小差车跑偏了;
l1和l2可以帮你刹车、调个方向盘,当然即便这样你也不能偷懒,全程都要盯着,否则一不注意,可能就修车店见了(前3级一般被当作辅助驾驶,真正的自动驾驶得到l3以上);
l3能在特定的道路中实现自动驾驶;
l4基本可以实现双手和大脑解放,除非情况危急,否则司机基本不用操心行驶问题;
l5则是完全自动驾驶,甚至无需驾驶员,不过目前还没有哪家公司能完美做到这一点。
智能驾驶核心技术
01
感知技术
我们平常开车,是怎么感知周围环境的?
很简单,眼睛看、耳朵听。
对于机器而言,我们可以使用摄像头、激光雷达、红外线、超声波雷达等传感器来代替人眼实现「看」的功能。
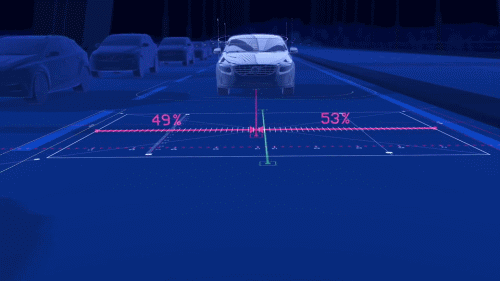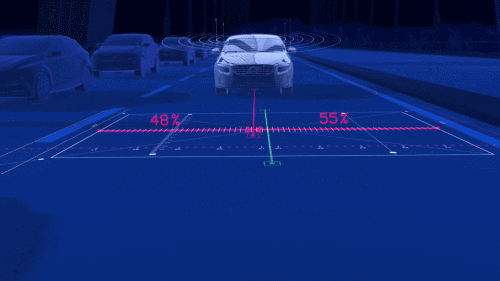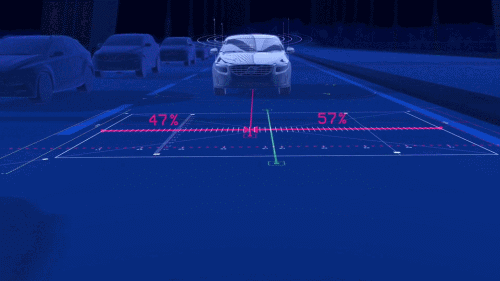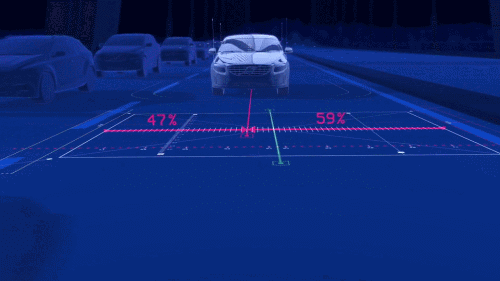
摄像头可以快速识别汽车尾灯、红绿灯、车道线、行人等,不过在光线微弱时可能功能受限,因此获取更多环境信息还需雷达帮忙。各种传感器各有所长,但也存在着局限性,如何实现多传感器融合技术也是科研人员需要攻克的难点之一。
02
数据处理技术
信息获取后交给决策层(放在汽车后方的主控电脑)处理,它可以迅速分析数据、做出判断,为汽车规划路线;其后位于执行层的控制系统就可以按照指令操控汽车前行了。
在自动驾驶领域,戴尔科技提供基础架构、技术、专业知识帮助组织创建现代数据管道并加快adas开发工作流。
据统计,l3级别的adas系统,需要50-100pb的海量数据和5000-25000核的计算资源;而到完全实现自动驾驶的l5级别,则需要超过2eb的数据量和100000核的计算资源,这就要求自动驾驶应用和服务提供商具备强大的计算能力。

(1)数据存储
前文提到,汽车在工作过程中将收集海量数据,这些数据的存储也是一门技术活。
戴尔科技采用全球领先的分布式数据湖技术,面对海量数据可提供高性能、高可用和高可靠性:
●文件切片后打散保存到每一节点的每块硬盘,可充分利用硬盘性能;
●集群可不中断地添加或删除节点,在线添加一个节点只需60秒;
●冷热数据自动分层,扩容缩容后数据可以自动再平衡,保持所有节点数据均衡;
●单一文件系统可用容量最高可达80pb,管理简单;
●同一份文件同时支持多种访问协议,无需安装客户端插件,对应用透明。
(2)数据管理
数据管理,即建立元数据与树状结构的存储路径之间的映射。
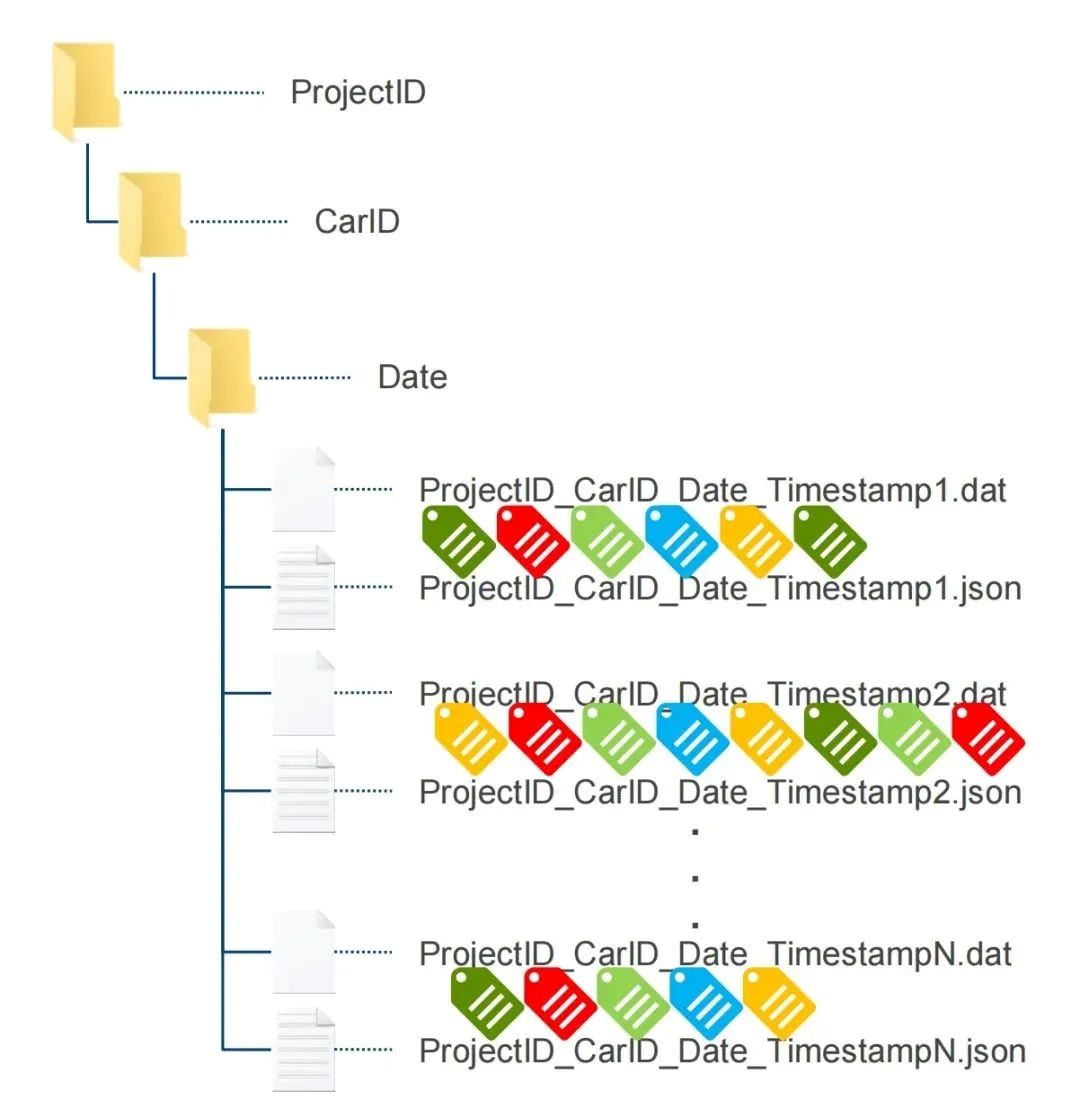
如上图显示,虽然现在的数据分层只有3级,但我们很难通过这样的树状结构快速定位到所需数据。实践中一般根据使用数据的业务场景,对这些数据打上标签,方便从业务视角定位数据,我们使用数据时会对数据标签进行动态的增、删、改等操作,因此数据维护是一个动态过程。
关于自动驾驶数据调用,戴尔科技提供了一套先进的元数据管理平台——dms,专为自动驾驶研发定制。
dms可实现两类功能:1.元数据的自动化导入;2.动态维护元数据与祼数据之间的映射关系。此外,dms还支持数据横向扩展,比如可以从万级数据扩展到亿级数据,保证搜索结果在极短时间内反馈给上层应用。

(3)数据访问
自动驾驶研发过程中,很多工作负载并行运行,它们同时访问数据湖中的元数据,并在算力侧按照不同的工作负载挖掘相应的数据价值。
传统做法是针对不同工作负载创建对应的副本,但在海量数据情况下,这会造成数据的极大冗余并消耗大量时间。
而戴尔科技采用的多协议并行访问可以克服以上弊端。在多协议并行访问模式下,无论写数据使用的是什么协议,都可以使用其它协议进行数据读取,无需分数据池、无需数据搬运,且支持自动分层。
这种做法有两大好处:
●工具链选择灵活性:既支持nfs协议,也支持smb协议。
●大幅节约数据搬迁时间:数据一旦进入数据湖,即可使用各种协议对其访问。
03
ai训练技术
如果将环境感知模块比作人的眼睛和耳朵,那么决策规划模块就相当于自动驾驶汽车的大脑,涉及汽车安全行驶、车与路的综合管理等多个方面,而ai训练技术则是决策规划模块的前提。

在人工智能、大数据、边缘计算等凯发在线的技术支持下,人们可基于传感器收集回来的数据对汽车状态、姿态进行实时监控,帮助决策模块做出相应动作。
那么在汽车行业智能化这个方向,ai可以做些什么呢?主要有以下几点:
自动驾驶(智能感知)、自动驾驶(智能决策)、数字孪生/合成数据生成、人机交互、ai 视觉产线缺陷检测、设备健康管理与预测性维护、智能仓储管理。
ai研发过程中,我们需要构建多级跨物理设备的算力集群为其提供算力支持,为实现更高效的模型收敛及应用开发,gpu分布式训练常常是行之有效的手段。
ai gpu分布式训练优化方面,戴尔科技开展了不少实践并取显著成果。
●使用6台戴尔poweredge xe8545服务器,24卡a100构建的gpu 集群,在tensorflow 分布式训练性能中可实现 88%-96% 的线性加速比。
●戴尔poweredge r750xa a100 gpu构建的计算集群,在mlperf training v1.1基准测试 resnet-50图像分类赛道中,2台、4 台poweredge r750xa分布式训练的计算性能分别为单台服务器的1.96倍和3.63倍。
自动驾驶是边缘计算的典型应用场景,nvidia认证的企业级边缘服务器一共51款,其中仅戴尔服务器就有31款,高居榜首。

04
数据安全技术
汽车收集的数据必然带有地理位置等敏感信息,因此必须在严格合规的情况下合理使用。这方面,戴尔科技以先进的数据保护技术全方位守护汽车数据安全。
◆可审计
提供审计功能与图商监管审计系统对接,可追溯用户的访问行为,确定哪些用户何时对哪些文件进行了什么操作。
◆可隔离
支持按不同项目或不同车型隔离数据,支持多租户功能,可按租户对数据进行安全隔离。
◆权限设置
支持基于角色的访问控制(rbac),细粒度设置权限和角色。
◆防删除
支持快照功能,可通过快照功能修复误删除等逻辑错误,单一集群支持不少于2万个快照;支持worm(一写多读)功能;可防止关键数据被恶意更改或删除,同时满足严格合规性要求和管理要求。
◆防病毒/防勒索
提供icap数据安全检测接口,供第三方杀毒软件直接进行数据的集中病毒检测和杀毒。结合superna ransomware defender和智能air gap,提供勒索病毒攻击检测,停止加密并一键实时恢复数据。
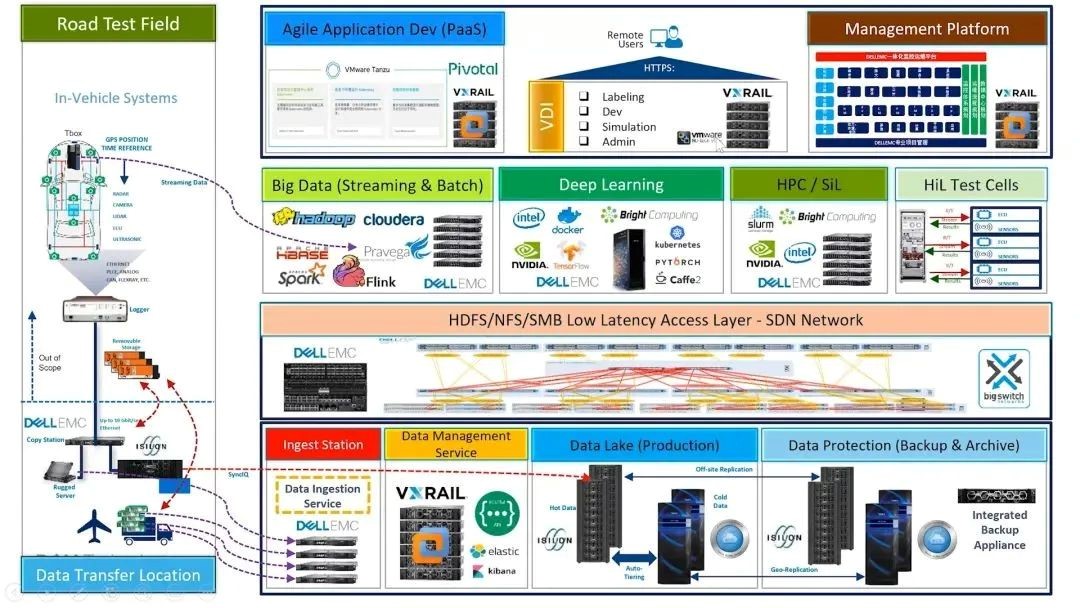
为助力自动驾驶的研发,戴尔联合英伟达推出如下参考架构,该架构已在全球多家客户落地使用,具有“快、准、省”三大特点。
随着时间推移,自动驾驶所处的政策环境越来越包容开放:
2003年我国法律上“不排斥”,2015年明确支持智能辅助驾驶的发展,2016年提出要重点发展“自动驾驶”,2020年国务院发布的《新能源汽车产业发展规划(2021—2035年)》提出,“到2025年,高度自动驾驶汽车实现限定区域和特定场景商业化应用”、“力争经过15年持续努力,高度自动驾驶汽车实现规模化应用。”
戴尔科技凭借丰富的产品和凯发在线的解决方案、业内领先的技术架构和信息与图像分析处理方面的雄厚实力,正为全球约80%的自动驾驶车企提供安全可靠的基础架构平台。相信在不久的将来,无人驾驶汽车满街跑的愿景必定会实现!
筑牢数字基座
是成为数智远见者的第一步
唯有全面提高企业韧性
方能做到行稳致远
接收下方邀请函
共同锻造企业“韧性”
释放数据无限潜能

如果您想了解更多有关戴尔科技的产品和凯发在线的解决方案信息,请扫描以下二维码咨询戴尔官方客服。







