
清华大学微纳电子系博士生涂锋斌在大会上做了题为《rana:基于刷新优化嵌入式 dram 的神经网络加速框架》(rana: towards efficient neural acceleration with refresh-optimized embedded dram)的口头报告。该研究成果大幅提升了人工智能(ai)计算芯片的能量效率。
涂锋斌的研究论文是今年大会中国唯一被收录的署名第一完成单位的论文。清华大学微纳电子系尹首一副教授为本文通讯作者,涂锋斌为本文第一作者,论文合作者还包括清华大学微纳电子系魏少军教授、刘雷波教授和吴薇薇同学。
fengbin tu, weiwei wu, shouyi yin, leibo liu, shaojun wei,「rana: towards efficient neural acceleration with refresh-optimized embedded dram,」international symposium on computer architecture (isca), los angeles, usa, 2018.

清华大学微纳电子系博士生涂锋斌报告现场。
论文详细信息如下:
1 研究背景
深度神经网络(dnn)已经被广泛应用在各种 ai 场景中。为了获得更高的精度,dnn 的网络规模也日益增大,导致网络数据存储量达几 mb 甚至几十 mb。此数据量甚至会随着输入图片的分辨率和批处理规模的增大而增大。然而,传统的基于 sram 的 ai 计算芯片,由于芯片面积的限制,往往只有几百 kb 的片上存储容量。因此,在运行当前的 dnn 时,片外存储访问难以避免,这会造成巨大的系统能耗开销。存储问题是 ai 计算芯片设计中必须解决的一个重要问题。
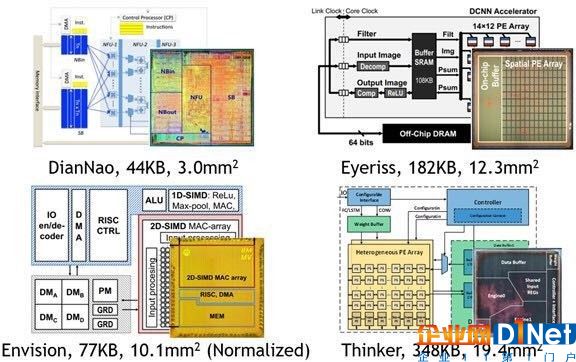
当前几款主流 ai 计算芯片(diannao、eyeriss、envision、thinker)及其存储、面积参数。
2 数据生存时间感知的神经网络加速框架(rana)
嵌入式 dram(简称 edram),相比于传统 sram 有更高的存储密度,可以替代传统 sram 作为片上存储以减少片外访问。然而,edram 存储单元中的电容电荷会随时间而逐渐丢失,因此需要周期性的刷新操作来维持 edram 的数据正确性。已经有研究证明,刷新能耗是 edram 总能耗的主要来源,而且会占据整体系统能耗的很大比重。因此,使用 edram 带来的额外刷新能耗开销不容忽视。本文发现,如果数据在 edram 中的生存时间(data lifetime)小于 edram 的数据维持时间(retention time),那么系统将不再需要对于此数据的刷新操作。由此可以得到两个优化方向:减少数据生存时间,和增大数据维持时间。
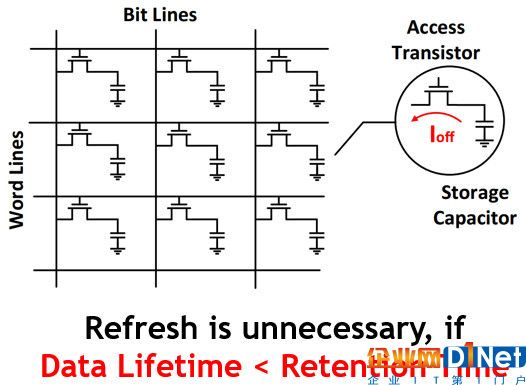
嵌入式 dram(edram)结构及本文核心观点。
本文提出一种基于 edram 存储器的新型加速框架:数据生存时间感知的神经网络加速框架(rana)。rana 框架采用 edram 作为片上存储器,相比于传统 sram 具有更高的存储密度,大幅减少片外访存。同时,rana 框架采用三个层次的技术:数据生存时间感知的训练方法,神经网络分层的混合计算模式和刷新优化的 edram 控制器,分别从训练、调度和架构三个层面降低 edram 刷新能耗,进而大幅优化整体系统能耗。
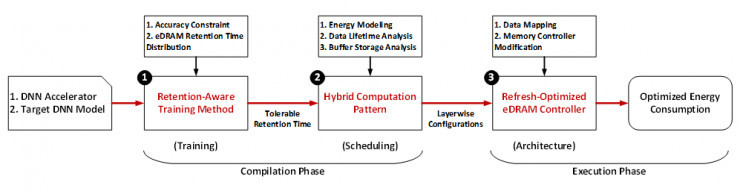
数据生存时间感知的神经网络加速框架(rana)。
2.1 训练层次优化:数据生存时间感知的训练方法
通常 edram 的刷新周期会设置为最差的存储单元所对应的数据维持时间,以保证程序执行过程中所有存储单元的数据都不会出错。而在一个实际 edram 存储器中,不同存储单元的数据维持时间是不同的。下图是一条典型的 edram 数据维持时间分布曲线。横轴是数据维持时间,纵轴是错误率,即低于给定维持时间的存储单元占所有存储单元的比例。对于一个 32kb 的 edram 而言,数据维持时间最短的存储单元通常出现在 45 微秒处,对应的错误率大约为 10^(-6) 量级。本文发现,适当增加数据维持时间,并不会显著地提升错误率。
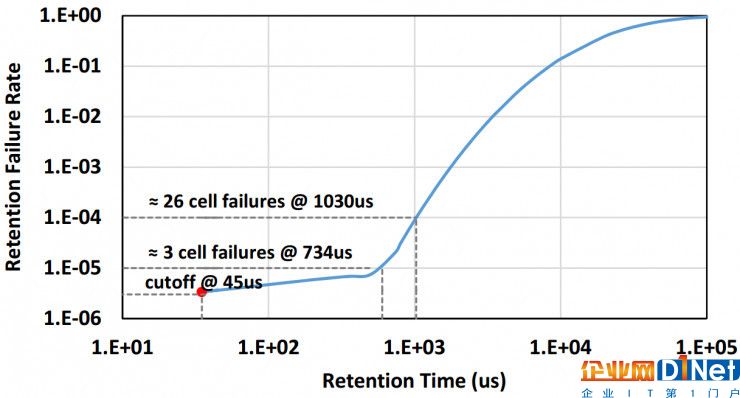
典型 edram 数据维持时间分布曲线。
本文利用 dnn 的容错能力来重新训练网络使其能承受更高的错误率,并获得更长的「可容忍」的数据维持时间。如下图所示,本方法在训练的正向过程中对输入和权重数据加入一个掩膜(layer mask)以引入误差。这个掩膜会以一定的错误率对每个比特注入误差。经过反复的重训练,如果最终的精度损失可以接受,那么就认为网络可以承受当前的错误率。本文发现,对于 alexnet、vgg、googlenet 和 resnet 四个网络,错误率提高到 10^(-5) 后网络精度仍没有损失,此时对应的「可容忍」的数据维持时间提高到了 734 微秒,因此更有机会以更低的频率刷新甚至消除刷新操作。
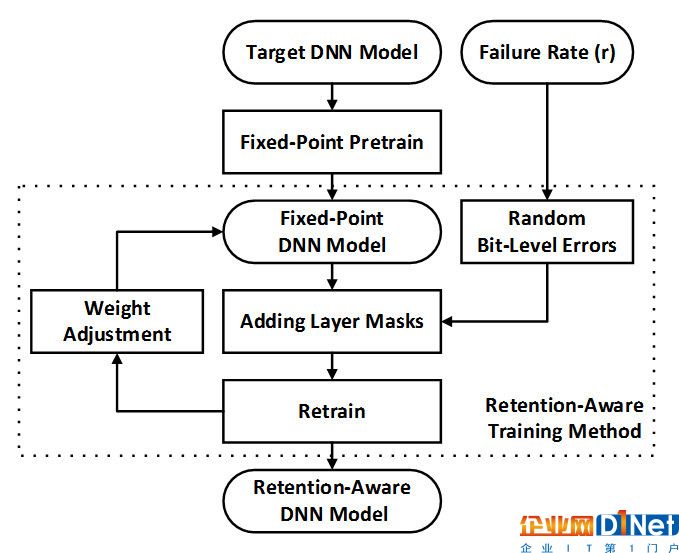
训练层次优化:数据生存时间感知的训练方法。
2.2 调度层次优化:神经网络分层的混合计算模式
下图所示是三种典型的计算模式,分别用多层循环的形式表示。本文发现,数据生存时间和片上存储需求与循环顺序,特别是最外层循环极为相关。在输入、输出和权重这三类数据中,输出数据的生存时间与另两种数据类型完全不同。与输入、权重这种静态存储在缓存中的数据不同,输出数据会在累加的过程中不断刷新。在每次刷新中,输出数据会被重新写入存储器,对 edram 存储单元重新充电进而恢复了之前丢失的电荷。这一过程和周期性刷新操作本质上是一样的。因此,如图所示,如果把输出数据作为最外层循环迭代变量,数据生存时间将会非常短。当然,此时必须在片上存下全部的输出数据以避免片外访存。
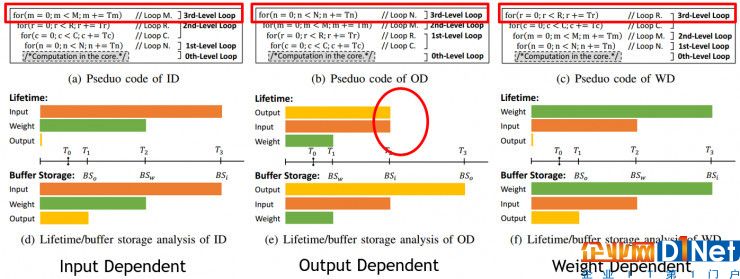
三种典型的计算模式及其生存时间/缓存需求分析。
本文提出神经网络分层的混合计算模式,根据芯片参数及 dnn 网络参数,对网络的每一层分配一个最优的计算模式。计算模式的探索过程被抽象为一个目标为系统能耗最小化的优化问题。具体调度方法如下图所示,调度结果会被编译成分层的配置信息(包括「可容忍」的数据维持时间、每层的计算模式及刷新标志),以用于执行过程的硬件配置。
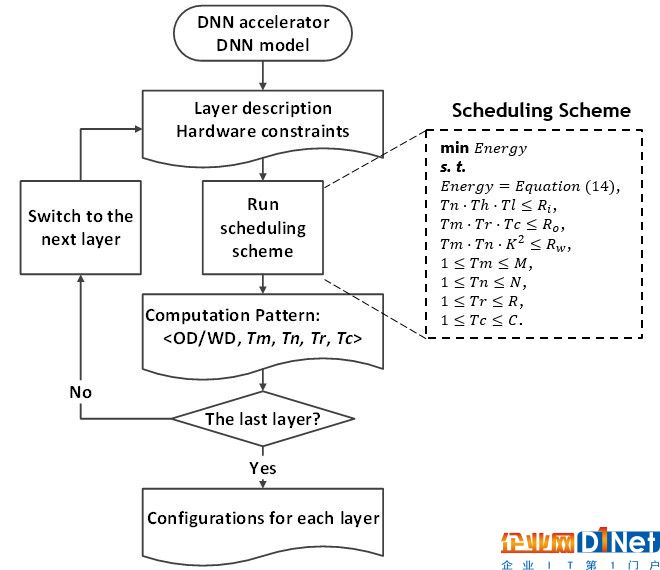
调度层次优化:神经网络分层的混合计算模式。
2.3 架构层次优化:刷新优化的 edram 控制器
在传统的 edram 控制器中,所有的 edram 分区都以最保守的刷新周期进行刷新。本工作对 edram 控制器稍加改造,加入一个可编程的时钟分频器、各 edram 分区独立的刷新触发器和刷新标志位。控制器的配置信息来自于前两个技术的编译结果,具体将决定每个分区分别存储什么数据类型、是否需要刷新以及刷新周期。
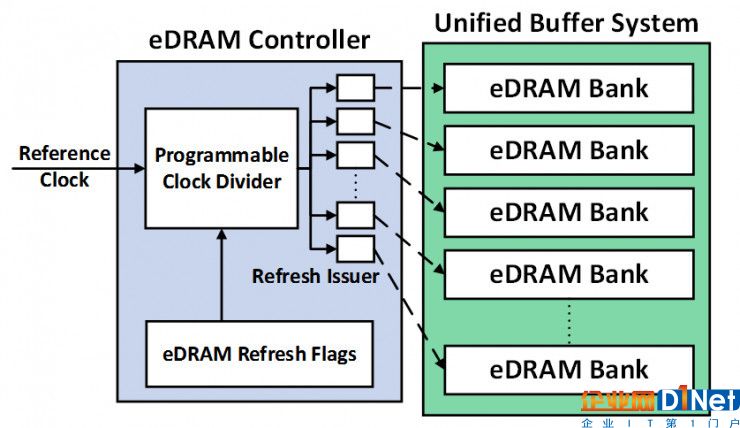
架构层次优化:刷新优化的 edram 控制器。
3 实验结果
下图为用于验证 rana 框架的实验平台具体配置:本工作实现了一款 ai 计算芯片来进行 rtl 级别性能功耗分析,以获得精确的性能参数和访存行为记录。

验证平台配置参数及芯片版图。
实验结果显示,rana 框架可以消除 99.7% 的 edram 刷新能耗开销,而性能和精度损失可以忽略不计。相比于传统的采用 sram 的 ai 计算芯片,使用 rana 框架的基于 edram 的计算芯片在面积开销相同的情况下可以减少 41.7% 的片外访存和 66.2% 的系统能耗,使 ai 计算系统的能量效率获得大幅提高。
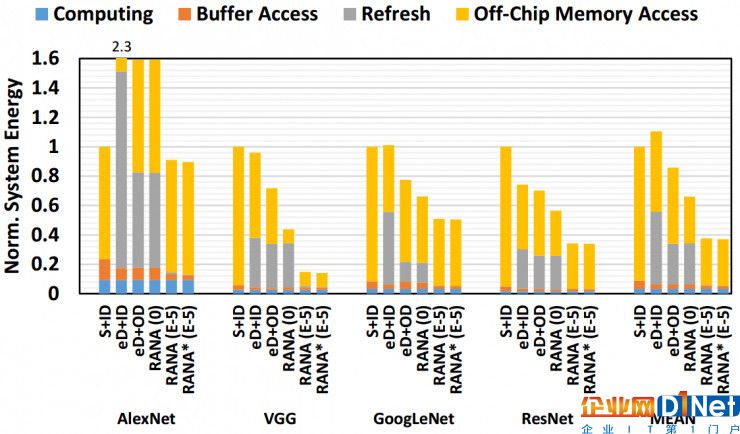
rana 框架系统级能耗分析。
4 总结
清华大学微纳电子系 thinker 团队近年来基于可重构计算架构设计了 thinker 系列 ai 计算芯片(thinker i,thinker ii,thinker s),受到学术界和工业界的广泛关注,在 2017 年曾获得 islped'17 低功耗设计竞赛冠军。thinker 团队此次研究成果,从存储优化和软硬件协同设计的角度大幅提升了芯片能量效率, 给 ai 计算芯片的架构演进提供了新思路。




